References
1. Introduction & Motivation
-
对于无约束凸优化问题 , 如果 是可微的, 我们可以用梯度下降法: 进行优化. 若 是 Lipschitz 连续的, 则可以保证其收敛速率为 .
-
当 不可微时, 我们可以使用次梯度方法 (subgradient method) 来进行优化: 类似地, 首先确定初始点 , 然后迭代更新:
其中 是 在 处的 subdifferential.
-
然而, 由于 subgradient 更新并不一定必然导致函数值的下降, 因此需要对每次的更新值进行追踪, 并记录迄今为止的最优值 .
2. Subgradient Algorithm
2.1 Step Size Selection
在更一般的非光滑优化问题中, 选择一个能同时保证收敛又能有效步进的步长往往是十分困难的, 因此往往是通过经验提前设定的, 常见的步长选择方法有:
- 固定步长: .
- 固定步进: , 其中 是一个常数, 这样保证每次更新的步长 是固定的.
- 平方收敛步长: 使得步长满足 和 , 例如 .
- 极限收敛步长: 使得步长满足 和 , 例如 .
3. Convergence Analysis
3.1 Assumptions
为分析方便, 额外添加如下假设:
-
是凸的, 且 .
-
最优值是有限的 () 且可达的 (存在 使得 ).
-
初始点 与最优点 之间的距离是有限的, 即 .
-
是 -Lipschitz 连续的, 即 对于所有 和 都成立, 或等价地 对于所有 都成立.
Proof of the Lipschitz/subgradient-bound equivalence
- 下给出两种表述的等价性证明.
- 由 推出 .
- 由于 , 根据 subgradient 的定义, 对于任意 , 都有 , 从而
- 由 Cauchy-Schwarz 不等式, , 从而 . 同理由对称性, 我们也可以得到 , 从而 .
- 由 推出 .
-
由 subgradient 的定义, 取单位向量 , 令 , , 则 , 从而
-
由 Lipschitz 连续性, . 因此 对于任意单位向量 都成立.
-
根据事实: , 可得 .
-
3.2 Basic Inequality & Convergence Analysis
首先给出如下基本不等式, 以便后续分析. 记 为历史最优值, 为初始点与最优点之间的距离, 为 的 Lipschitz 常数, 为第 次迭代的步长, 为最优值, 则对于任意 , 都有:
Proof of the basic inequality
首先证明 .
由 subgradient method 的更新公式, 有 .
由 subgradient 的定义, , 从而 . 因此上不等式最终可以化为:
接下来, 将上述不等式进行迭代展开 , 并根据 , 因此 对于所有 都成立 ,以及 的假设, 可以得到:
进而整理得到:
若进一步利用 的 Lipschitz 连续性, 即 对于所有 , 则可以得到:
-
对于不同的步长策略, 上不等式可以进一步进行化简整理.
-
对于固定步长 , 上式可以化简为:
-
对于固定步进 , 将其带入 Lipschitz 连续性化简前的不等式, 可以得到:
-
对于平方收敛步长 和 , 上式可以化简为:
-
-
总的而言, 其一般的收敛速率为 , 这一速率是非常缓慢的. 如果观测其收敛上界 , 由 Cauchy-Schwarz 不等式可以给出理论的最快收敛情况在等步长 时达到, 此时上界为 , 从而可以得到 的收敛速率. 此外, 这个停止条件依赖 之类的全局常数, 现实里通常不知道, 而且即便知道, 它也只给出一个极其保守的最坏情况保证.
Example (Subgradient method on a maximum of affine functions). 考虑如下的非光滑优化问题:
对于该函数, 在之前的章节中提供了其 subgradient 的计算方法, 这里记之为 . 下分别考虑通过固定步进和几种衰退步长的 subgradient method 来进行优化, 其迭代更新公式如下:
-
固定步进: , 分别取 .
-
观察到初期下降速度很快, 但是后面会进入平台期. 并且根据 的不同, 平台期的水平也不同. 由于 因此 越小, 平台期的水平越低, 但下降速度也越慢.
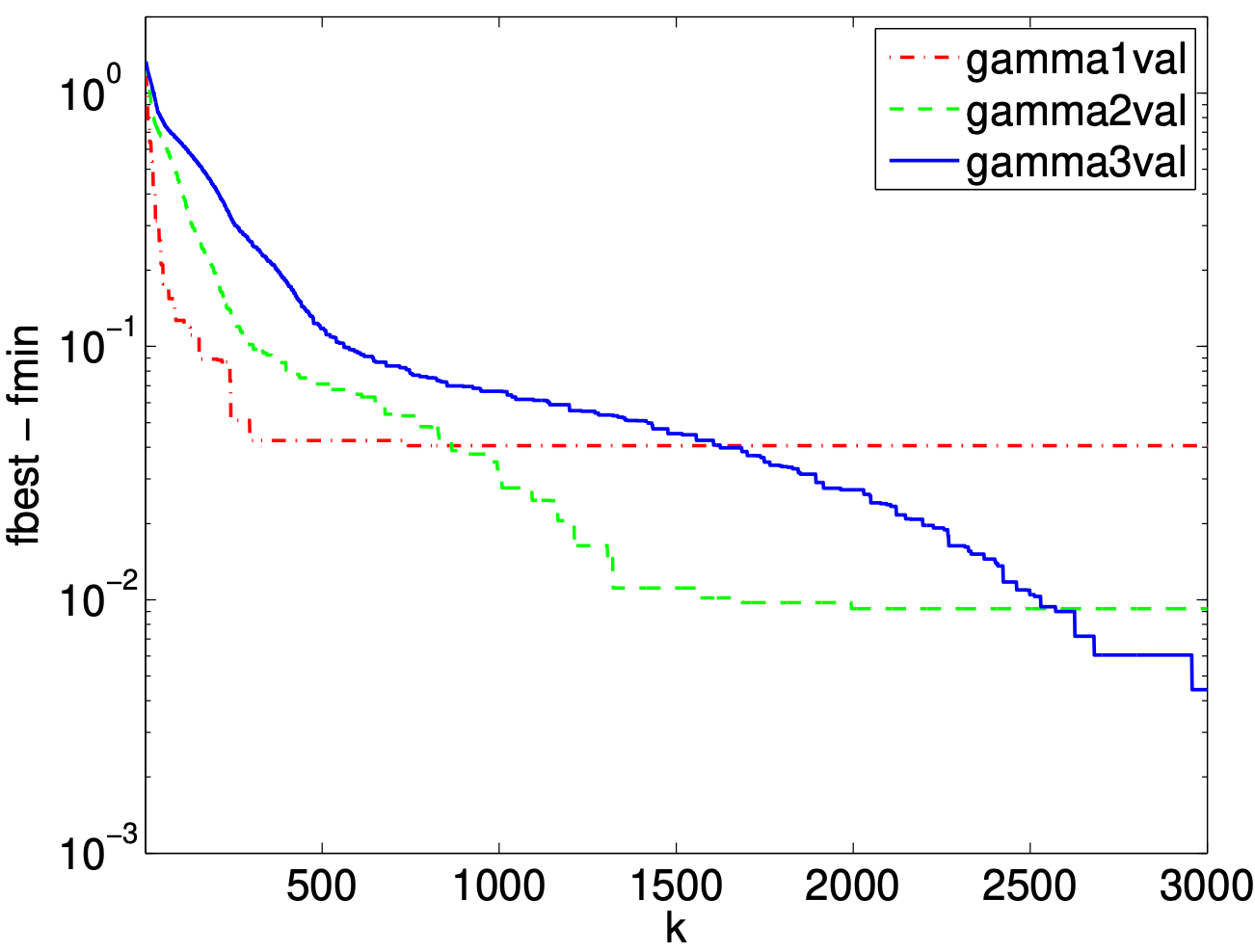
Figure: Fixed-step subgradient method comparison.
-
-
衰退步长: , 分别取 .
-
观察到不同常数系数差异巨大: 系数过大前期抖动更明显, 过小则整体太慢. 这也说明 subgradient 对步长非常敏感, 调参是主要成本. 此外, 衰减型相比于固定步进, 下降速度更慢, 但没有明显的平台期, 这也符合理论分析.
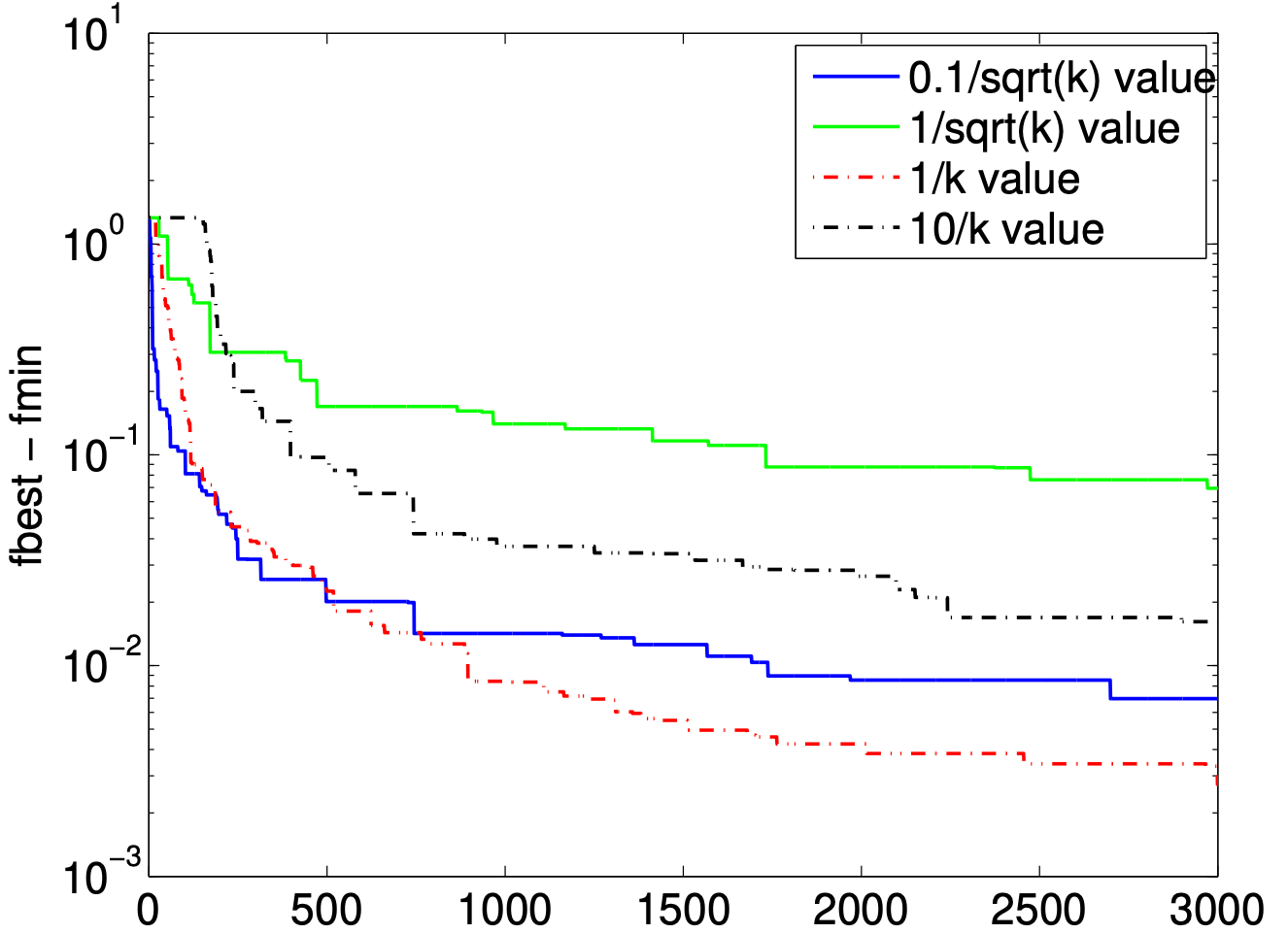
Figure: Diminishing-step subgradient method comparison.
-
3.3 Polyak: Optimal Step Size when is Known
在理想分析中, 是已知的, 因此可以选择如下的 Polyak 步长:
-
Polyak 的更新思想很简单: 利用当前的函数值和最优值之间的差距来动态调整步长, 使得每次迭代都能最大程度地减少当前点和最优点之间的距离. 然而, 由于 在实际问题中通常是未知的, 因此 Polyak 的步长虽然在理论上是最优的, 但在实践中很难直接使用.
-
回顾在之前的基本不等式中, 利用 subgradient 的定义, 可以得到:
而 Polyak 的步长恰好为使得 RHS 最小的步长, 即其最大程度控制了下一次迭代位置和最优点之间的距离.
-
将该最优步长代入, 可得不等式:
-
该式立刻保证 , 从而保证了每次迭代都不会使得当前点和最优点之间的距离增加.
-
令 , 将上述不等式进行迭代展开, 可以得到:
-
再分别利用 的 Lipschitz 连续性 和 的假设, 可以得到:
即证 .
-
在实践中, 有时可以通过 Estimated Polyak 步长来近似 Polyak 步长. 具体地, 用目前为止观测到的最优值 来近似 :
- 其中 是一个小的正数避免止步长为零. 往往也会选择满足 Robbins-Monro 条件的衰减步长 (即 和 ), 以保证其在理论上能够收敛到最优值, 例如 .
- 可以证明, 估计的历史最优值会逐渐逼近最优值.
3.4 General Convergence Result
对于一般的一阶非光滑算法:
对于 weak oracle (查询一次, 只能得到函数值 和一阶 这类有限信息, 没有更强的二阶信息或全局结构), 此时有定理保证对于任何 及任意初始点 , 都存在一个目标函数使得
- 该定理表明, 在最坏的情况下, 任何一阶非光滑优化算法在 次迭代后都无法保证其函数值与最优值之间的差距小于 . 这也说明了 subgradient method 的 的收敛速率是最优的.
不过, 该定理实在说明在一般情况下的收敛水平. 对于具有特殊结构的非光滑优化问题, 可能存在更快的算法. 例如考虑如下的 composite 结构:
- 是一个凸且可微 (通常还进一步假设其梯度是 Lipschitz 连续的) 的函数
- 是一个凸但不可微的函数, 但其相对容易计算的 此时可以通过利用这些特殊结构将效率提升为 , 例如 Proximal Gradient Method.
4. Further Applications of Subgradient Methods
4.1 Alternating Projections
考虑求解凸集交的问题. 这里将说明此类问题的对应解决方法 (即 alternating projections) 是 subgradient method 的一个特殊实例.
-
问题的叙述为:
其中 是 中的凸集.
-
可通过如下方法将问题转化为一个非光滑优化问题:
-
定义投影点 . 定义点 到集合 的距离为 .
-
注意到 当且仅当 对于所有 都成立, 因此可以将原问题转化为如下的非光滑优化问题:
-
-
由于 是 convex 的, 因此 也是 convex 的. 因此可以通过 subgradient method 来进行优化.
-
计算每个分量的 subgradient: 对于集合 及点 , 其距离为 .
- 当 时, , 此时 是 在 处的 subgradient.
- 当 时, , 此时 是 在 处的 subgradient.
-
因此对于 , 记 为最大值对应的索引集合, 则
-
-
进而 subgradient method 的更新公式为:
因此, 在每次迭代中, subgradient method 都会将当前点 投影到距离其最远的集合 上. 这就是 alternating projections 的核心思想. 通过不断地交替投影, 可以逐渐逼近交集 中的一个点.
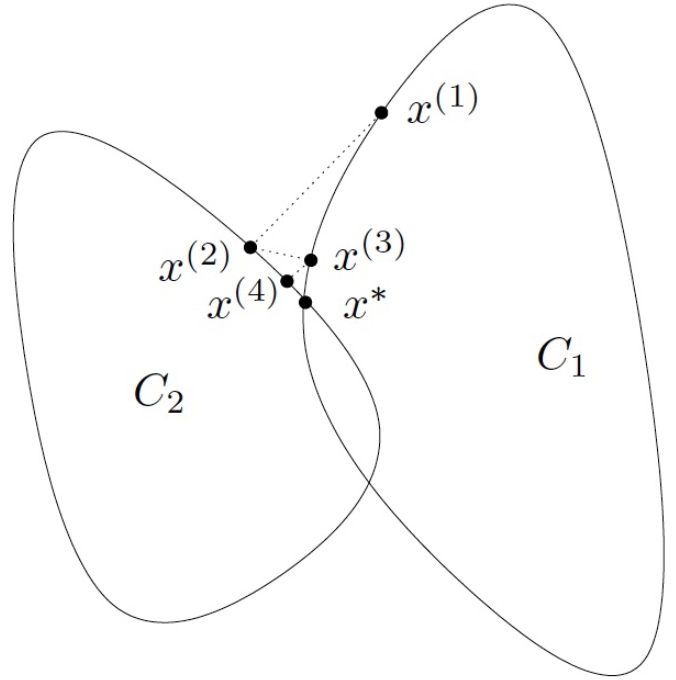
Figure: Alternating projections.
4.2 Projected Subgradient Method
考虑非光滑凸有约束优化问题:
由于约束条件的存在, 直接进行 subgradient method 的更新可能会导致迭代点 不满足约束条件. 因此, 可以通过在每次迭代后进行投影来保证迭代点始终满足约束条件. 具体地, 其更新公式为:
其中 是将点 投影到集合 上的操作.
- 只要这个投影是便于计算的, 那么 projected subgradient method 就是一个非常实用的算法. 其步长的选择规则等也与之前的无约束情况类似, 例如固定步长、衰减步长等.