References
- Lecture: https://www.stat.cmu.edu/~ryantibs/convexopt-F18/
- Reading: 最优化:建模、算法与理论,刘浩洋等,第 8.1 节、第 8.3 节.
1. Proximal Gradient Descent
1.1 Decomposable Functions (Composite Objective)
在统计建模中, 目标函数经常能够分解成两个部分的和, 其中一个部分是光滑的, 另一个部分是非光滑的. 例如, Lasso 回归中的目标函数可以分解为平方损失函数(光滑)和 L1 正则化项(非光滑). 形式化地, (暂时只考虑凸函数) 我们可以将目标函数表示为:
- 是光滑凸函数, 不妨令 . (更一般地, 只需 在算法迭代点所在区域可微且 满足 Lipschitz 条件; 若 的定义域带来约束, 可将对应指示函数并入 .)
- 是非光滑的凸函数, 但具有简单的结构, 使得我们能够高效地计算其近端算子(proximal operator).
在处理这样的优化问题时传统的梯度下降方法可能无法直接应用, 因为 的非光滑性会导致梯度不存在; 而若直接使用次梯度方法, 则可能会导致收敛速度较慢.
因此我们需要一种新的优化方法来处理这种分解结构的目标函数, 这就是近端梯度下降(Proximal Gradient Descent) 方法. 其对于光滑的部分 使用梯度信息, 对于非光滑的部分 则利用其近端算子来进行优化.
回顾一下, 传统的梯度下降方法在每一步迭代中更新参数 的方式为: . 我们选择 , 是因为对 在 处做一阶近似并加上二次正则后, 有:
- 其中, 二次项是相当于将泰勒展开中的二次项 用 来近似的结果.
- 也可理解为: 给一阶线性化模型加上一个强凸的 proximal 正则项, 从而得到步长为 的显式更新.
- 而 的选择使得 成为上述近似目标函数的最小值: .
在当前的 Decomposable/Composite Objective 设置中, 先区分原问题的全局最优点与一步更新点:
在当前点 处定义局部上界模型(surrogate)
对 做配方并去掉与 无关项, 可得
- 这个更新步骤的核心思想是: 在每次迭代中, 首先对光滑部分 进行梯度下降的更新, 得到一个临时变量 ; 然后通过最小化包含非光滑部分 的二次近似目标函数来得到新的参数 .
1.2 Proximal Operator
事实上, 上述推导的最后一步, 若将 当作一个新的输入, 那么这就是一个在给定非光滑函数 的情况下, 进行近端映射的过程. 即:
Definition (近端算子). 对于一个凸函数 (proper, closed, convex), 其近端算子 定义为:
- 其中, 是输入向量, 是优化变量, 与 在同一空间中. 该算子相当于在 的基础上进行一个平滑的调整, 使得调整后的点能够在最小化非光滑函数 的同时尽可能接近 .
其具有如下性质: 对于适当的闭凸函数 :
- 对任意 , 都是存在且唯一的.
- 这保证了近端梯度下降方法在每次迭代中都能够得到一个明确的更新结果.
- 等价于 , 其中 是 在 处的次微分.
-
近端算子所得到的点 与输入点 之间的差异正好对应于 在 处的次梯度信息.
Proof of the prox/subgradient equivalence
-
若已知 , 则 是以下优化问题的最小值: . 因此 , 从而
-
若 , 则由次梯度定义可知 , 从而
从而 .
-
进一步, 用 来缩放函数 , 则有:
Definition (缩放的近端算子). 对于一个凸函数 以及一个正标量 , 其缩放的近端算子 定义为:
- 该算子与未缩放的近端算子类似, 但在优化目标中对函数 进行了缩放, 这在实际应用中可以调整近端映射的强度.
- 与 的写法完全等价 (只差一个正数倍缩放).
- 上述和次梯度的关系同样成立: 等价于 .
Example ( 的 prox 算子). 对于 其中 及 , 其 prox 算子 的计算结果为:
1.3 Proximal Gradient Descent Algorithm
对于可分解的凸优化问题:
- 其中 是光滑凸函数, 是非光滑凸函数. 我们可以通过近端梯度下降算法来求解该问题.
- 事实上, 对于含约束的优化问题同样也可以令 (其中 为非空闭凸集) 来将约束条件隐式地包含在非光滑函数中, 从而使得近端梯度下降算法同样适用.
Proximal Gradient Descent 的迭代更新步骤如下:
-
初始化: 选择一个初始点 和一个步长参数 .
-
迭代更新: 对于 进行以下更新:
- 其中, 是当前迭代的参数, 是光滑部分 在 处的梯度, 是步长参数且同样可以设置为常数或通过线搜索等方法自适应调整, 是非光滑部分 的缩放近端算子.
-
当 时, 该算法退化为传统的梯度下降方法:
-
当 时, 该算法退化为投影梯度下降方法:
观察上述迭代更新, 其还可以等价表述为:
-
其中第三个等式中
被称为近端梯度映射(proximal gradient mapping).
-
其在某种意义上可以看作是一个综合了光滑部分梯度信息和非光滑部分次梯度信息的复合梯度, 其作用也相当于传统梯度下降法中的搜索方向.
-
Proximal Gradient Mapping 与次梯度的关系为:
-
此外 还具有如下性质: 当且仅当 是 的一个最优解.
-
-
第四个等式也显式地展示了近端梯度下降相当于对光滑部分进行梯度下降的同时, 对非光滑部分进行隐式梯度下降. 推导如下:
-
根据更新规则 以及 prox 算子与次梯度的关系, 可知:
-
从而存在 使得 , 即
-
2. Examples
2.1 ISTA for Lasso Regression
给定 和 , Lasso 回归的目标函数为:
-
其中 是光滑凸函数, 是非光滑凸函数.
-
利用 proximal gradient descent 方法, 首先分别求解梯度与近端算子:
- , 其中 是软阈值函数(soft-thresholding function).
-
因此, proximal gradient descent 的迭代更新步骤为:
该步骤也可以化作如下分步进行的形式:
- 首先计算一个临时变量 , 这相当于对光滑部分 进行梯度下降的更新.
- 然后对 进行软阈值处理 , 这相当于对非光滑部分 进行近端映射的处理.
-
该算法被称为迭代软阈值算法(Iterative Soft-Thresholding Algorithm, ISTA), 是一种求解 Lasso 回归问题的经典方法.
2.2 Low-rank Matrix Completion
给定一个矩阵 以及一个索引集合 表示已知的矩阵元素索引, 低秩矩阵补全的目标函数为:
该优化问题进一步可以通过 Nuclear Norm 的松弛来转化为如下形式:
- 可以证明该形式是一个凸优化问题.
若进一步考虑到观测数据中可能存在噪声, 则可以将约束条件松弛为一个正则项, 从而得到如下优化问题:
- 其中 是一个正则化参数, 用于平衡核范数正则项与数据拟合项之间的权重. 当 时, 否则 . 表示元素级乘法. 是 Frobenius 范数, 定义为 .
- 该优化问题同样可以通过 proximal gradient descent 方法来求解:
- , 其中 是 的奇异值分解(SVD), 且 对向量逐元素作用.
- 因此, proximal gradient descent 的迭代更新步骤为:
3. Backtracking Line Search for Proximal Gradient Descent
对于 proximal gradient descent 方法, backtracking line search 同样成立, 只不过其搜索对象是分解后光滑部分 的梯度.
整体而言, 给定 及初始化 , backtracking line search 的步骤如下:
-
先计算
-
检查条件
-
若不满足, 则令 , 并重新计算 与 后再次检查.
-
等价地, 也可写成更常见的上界模型检验: .
且有
在搜索过程中, 由于 本身依赖于 , 每次缩步长都必须重新计算 prox 映射.
不过还需要额外指出, 在 proximal gradient descent 中, 存在比 backtracking line search 更加高效的步长选择方法.
4. Convergence Analysis
4.1 Algorithm and Assumptions
回顾完整的 proximal gradient descent 算法. 考虑如下优化问题:
- 其中 是光滑凸函数, 是非光滑的凸函数.
Proximal gradient descent 的迭代更新步骤为:
- 其中 是 proximal gradient mapping.
在进行收敛性分析之前, 明确如下假设:
- 在定义域 上是凸且其梯度 是 -Lipschitz 连续的, 即对于任意 , 都有 .
- 是一个适当的闭凸函数, 使得其近端算子 是良好定义的.
- 目标函数 的最小值 是可达且有限的, 并在某个点 处达到. 不过这里并不要求 是唯一的.
4.2 Convergence Rate
在上述假设条件下, proximal gradient descent 方法的收敛性由以下定理保证:
Theorem (Proximal Gradient Descent 的收敛率). 在满足上述条件, 并给定步长 的情况下, 迭代序列 满足
即迭代点 的函数值以 的速率收敛到最优值 .
Proof of the convergence rate
根据假设中的 -Lipschitz 连续性, 对 进行二阶泰勒展开的上界估计, 可得对于任意 , 都有:
- 令此处的 , 则有:
- 根据步长假设 , 可得 . 从而:
另一方面, 根据假设 均为凸函数, 对于任意 , 都有:
其中 , . 从而若将 代入 的不等式中, 则有
- 其中 是根据 prox 算子与次梯度的关系得到的结果, 见 .
将 三个不等式相加, 并根据 composite objective 的定义 , 经整理化简, 对任意 都有:
若另记 , 则上式可以化作如下形式:
令 , 则有:
- 这表明每次迭代都会使得函数值至少下降 , 从而保证了函数值的单调不增.
特别地, 令 , 则有:
- 其中第二行的等式是通过单纯的代数整理得到的: .
因此从 开始迭代, 可以得到如下递推关系:
将上述不等式两边同时求和, 则有:
从而由于 是单调不增的, 可得:
从而得到最终的收敛率结果:
如果我们使用 backtracking line search 来选择步长, 我们可以从某个 开始, 通过不断缩小 来不断回溯, 直到满足条件:
并且每次缩放 后都要重新计算 与 . 并且可以由类似的分析过程来证明, 在满足上述条件的情况下, 其收敛情况为:
并且在常见 backtracking 设置下, 可由 给出一个粗下界.
5. Special Cases
根据 Decomposable/Composite Objective 的组成不同, 我们还有一些特殊的优化算法可以看作是 Proximal Gradient Descent 的特例.
5.1 Projected Gradient Descent
由 Proximal Gradient Descent 的定义可知, 当非光滑部分 是一个指示函数 且 为非空闭凸集时, 其近端算子 就退化为一个投影算子 且解唯一. 因此, 在这种特殊情况下, Proximal Gradient Descent 就退化为传统的投影梯度下降(Projected Gradient Descent) 方法. 其迭代更新步骤为:
- 其中 是将 投影到集合 上的操作.
- 其含义即为: 在每次迭代中, 首先对光滑部分 进行梯度下降的更新, 得到一个临时变量 ; 然后将 投影到约束集合 上, 从而得到新的参数 .
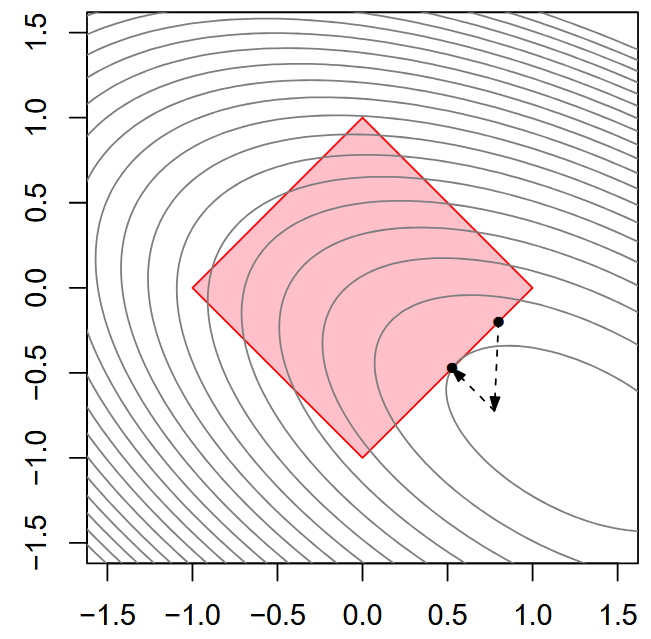
Figure: Projected gradient descent.
5.2 Proximal Point Algorithm
当光滑部分 恒为零时, 考虑如下优化问题:
- 其中 是一个适当的闭凸函数, 并不要求其具有可微性.
对于上述优化问题, Proximal Gradient Descent 的迭代更新步骤退化为:
6. Acceleration: Nesterov’s Accelerated Gradient Method
对于优化问题
使用 Proximal Gradient Descent, 如果光滑部分的函数 是 -smooth 的, 则目标函数的收敛速度为 . 但是, 通过一些加速技巧, 可以将收敛速度提升到 . Nesterov 在 1983, 1988, 2005 年提出了三种改进的一阶算法. Beck 和 Teboulle 在 2008 年给出了 Nesterov 1983 算法的 Proximal Gradient 版本, 被称为 FISTA(Fast Iterative Shrinkage-Thresholding Algorithm).
6.1 FISTA Algorithm
FISTA 的算法步骤如下:
- 初始化: 选择一个初始点 , 并令
- 迭代更新: 对于 进行以下更新直到满足收敛条件:
其还有一种表述形式:
- 初始化: 选择一个初始点 , 并令 . 选定加速参数 .
- 迭代更新: 对于 进行以下更新直到满足收敛条件:
- 计算
- 选择 , 计算
- 计算
当 且步长固定时, 上述两种表述形式是等价的.
对于 FISTA 算法, 在步长 和加速参数 满足如下条件的情况下 (此处 notation 以第二种表达形式为准), 其收敛率为 :
- ; 对于 ,
- .
在满足上述假设条件, 并在固定步长 的情况下, FISTA 迭代序列 满足
- 特别地, 当取 时, 上式退化为常见形式:
6.2 Line Search for FISTA
对于 FISTA 算法, 其步长 的选择同样可以通过 backtracking line search 来进行调整.
最基础的一个版本的 line search 过程如下:
- 初始化: 选择一个初始点 , 并令 . 选定加速参数 .
- 迭代更新: 对于 进行以下更新直到满足收敛条件:
- 计算
- 通过 line search 来选择 并更新 (给定迭代起始搜索步长 , 以及缩放因子 ):
- 计算
- 若 , 则
- 令 ,
- 重复上述计算 和条件检查, 直到满足条件为止.
- 返回满足条件的 和对应的 .
- 计算
其问题在于: 对于第 次迭代, 其 line search 的初始步长 的选择总是取为 , 这导致其在迭代过程中是不断缩小步长的, 从而可能会导致步长过小, 进而影响算法的收敛速度.
通过其他一些改进的 line search 方法, 可令条件 2 取等号
等价地
这是关于 的二次方程. 通过求解该方程来动态调整 和 , 可以在保证满足 line search 条件的同时, 使得步长 不会过快地缩小, 从而提升算法的收敛效率.
6.3 Several Remarks on FISTA
加速方法并不是适用于所有问题的.
-
例如在 warm start 的情况下 (例如在求解 Lasso 路径问题 , 其中 是一系列递减的正则化参数), 由于每次迭代的初始点 已经非常接近最优解, 因此加速方法可能会导致过度震荡, 从而反而降低收敛效率.
-
另外还比如在矩阵补全问题中, prox 的计算涉及到奇异值分解(SVD), 其计算复杂度较高. 需要区分两点:
- 若固定步长且不做回溯, ISTA 与 FISTA 的单次迭代主成本通常都由一次 prox(SVD) 主导, 基本同阶.
- 若使用 backtracking line search, 一次迭代内可能触发多次 prox(SVD) 重算, 这才会显著提高单次迭代开销.